
A Primer on Machine Learning: A Glimpse in the Machine Learning Mindset
For some years now, AI and Machine Learning are part of widespread media. Still, understanding of what Machine Learning is not self-evident. What does it even mean for a machine to learn something and what types of learning are there? How do ML algorithms work and what are some important limitations?
In this blog post, we seek to create some clarity on some of the basic concepts of the field, as well as dive into the specificities that Machine Learning algorithms imply for the working processes. We also explore the famous black-box problem that most Machine Learning algorithms encounter and why it is so relevant for the field. This will help create a better understanding of why the Machine Learning mindset is special.
Machine Learning Concepts
The first requirement for understanding the Machine Learning mindset is to have clarity on some of the most basic definitions of the field.
Algorithm. The concept of algorithm has grown to have a life of its own. Phrases like the “Google algorithm ranks pages…” or “Facebook’s algorithm shows (…) in your feed” are widespread. But an algorithm is something more basic. It is defined as a set of rules or a process that is followed to solve a problem. The classical example is the kitchen recipe (rules) to make a cake (solve a problem).
Artificial Intelligence. Artificial Intelligence is the study of how to make computers do things at which, at the moment, people are better.[1] This means that we find ways to teach machines to do things that we considered to require intelligence (e.g. respond to the environment). It is a broader concept than Machine Learning. The origins of Artificial Intelligence are not new, they are usually situated with humans’ quest to describe thinking as a symbolic system. However, the official term “Artificial Intelligence” was coined in 1956, at a conference that took place at Dartmouth College.
Machine Learning. Although it might sound a bit paradoxical since we usually think that learning is an activity exclusive to human beings (or at least to beings that are alive), Machine Learning consists of methods that are used so machines learn (something that we consider very smart, and in this sense, it is part of Artificial Intelligence). The key idea is that the machine is fed with data and they learn patterns according to some optimization or assessment of performance. Interestingly, a big source of inspiration for scientists to make machines learn has been the human brain. Typically, three types of learning methods are distinguished depending on the way the input data allows the machine to learn from it.
– Supervised Learning: This is the most common type of learning in the field. These methods use datasets that are labeled. This means that, for whatever one wants to classify or predict, there is a dataset that has the right answers. The methods then find the characteristics (features) within the dataset, that are helpful to make a prediction.
– Unsupervised Learning: In contrast to supervised methods, here the method does not use as input datasets that are labeled. This means that there is no identified output or feedback mechanism that the algorithm can use to learn structure from the data. These methods are quite popular to reduce the dimensionality of data sets and to create clusters in data sets where there is no knowable structure.
– Reinforcement Learning: The newest brand of Machine Learning and that is quite in vogue because it is proving to be quite successful. These methods are characterized by the ability of the machine to interact with its environment through trial and error to figure out what the best outcome is. This implies that a positive or negative reward system is defined, the interaction then consists of sequential decision-making problems in which they maximize rewards over time. There are no labeled cases, but in each state, the machine receives a reward signal.
Data Science Workflow
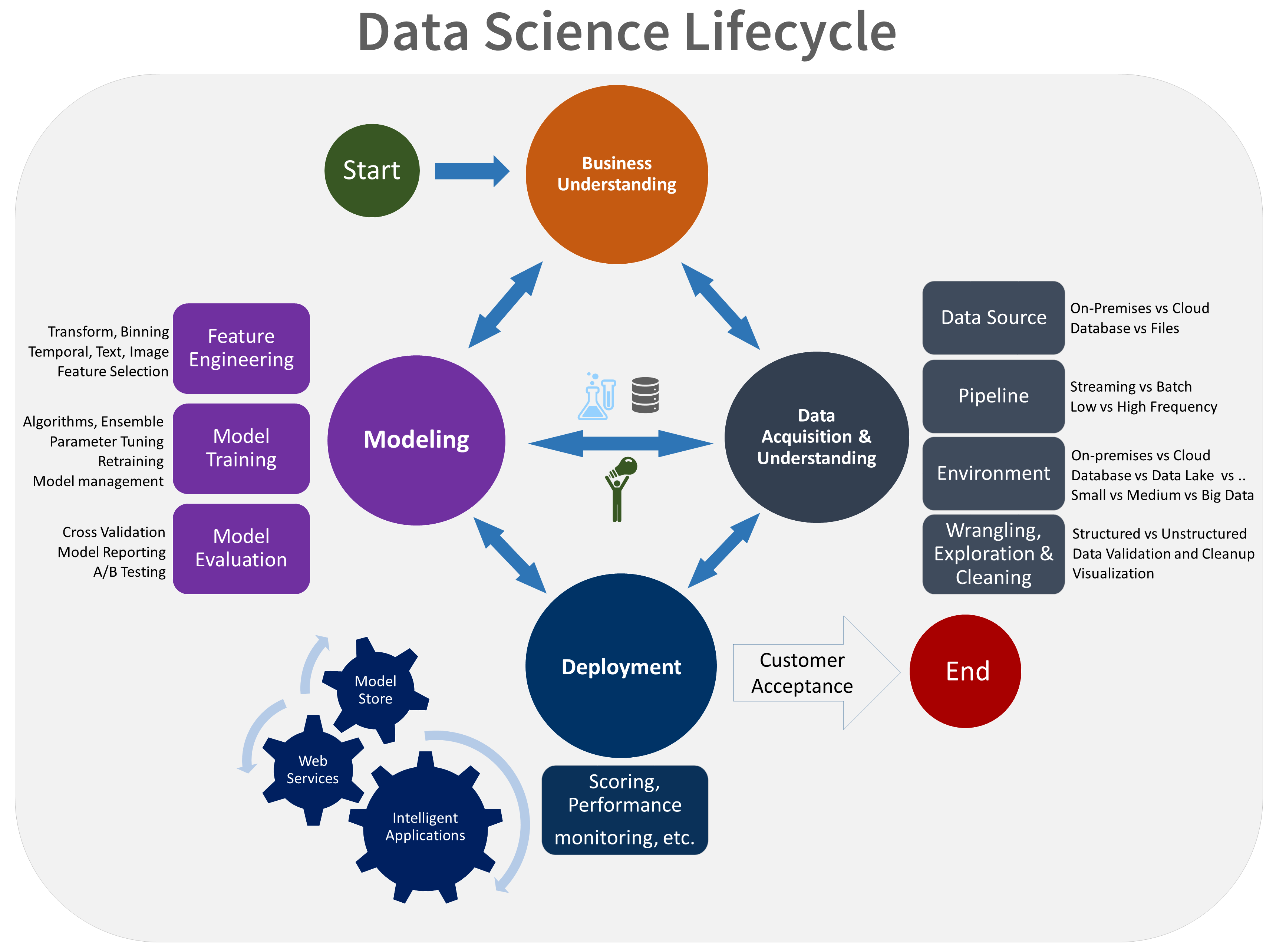
One of the most common questions we get from our clients is how a typical Machine Learning workflow looks like. In our previous post on a successful data strategy, we briefly mentioned the Data Science Lifecycle that Microsoft developed as an update of the traditional CRISP model. To understand the Machine Learning mindset, it is necessary to understand the specificities that ML brings to the working processes. Here we dive deeper into each of the traditional steps:
1. Business Understanding First, as in any Data Science project, a relevant business/marketing problem is identified (e.g. increase profits and customer satisfaction through recommendations of new products). Projects that do not start with a deep understanding of their business relevance are less likely to be successful.
2. Data Acquisition and Understanding. The next step consists of analyzing the availability of data to decide if it is feasible to solve the chosen business problem with Machine Learning techniques (e.g. purchasing behavior of clients, characteristics of products, external information about the characteristics of clients). This step is often overlooked or dismissed resulting in frustration later on when the models do not turn into accurate enough predictions. The IT department or Data Engineer will then be in charge of building the necessary infrastructure (e.g. databases and pipelines) for Data Scientists to get high-quality information to use in the next step.
3. Modeling. Data Scientist(s) uses Machine Learning algorithms to build a model that optimizes the results. Several different models can be tested against each other. Important steps are:
3.1 Feature Engineering. The art of selecting the inputs that the machine will use to learn (e.g. demographic information, consumption data, etc.). One condition for success is a deep understanding of the business problem.
3.2 Model training. For most ML algorithms it is necessary to split the data into two parts: with one part, Data Scientists build the models and with the other part the assess their performance. Building a model means writing the code that will tell the machine what it needs to optimize and, in most cases, which parameters to take into account. How machines choose to use these inputs to make predictions is, for most ML methods, a mystery (they are said to work like black boxes, more on that on the next section).
3.3 Model evaluation. With the second part of the data, the performance of the models is assessed. Why is it necessary to use fresh data (that the machine has not “seen”)? If the same data is used twice, to build models and to assess them, the assessment would predict that they perform better than they do in real life, because the models are tailored to this precise dataset that is just a subset of reality. Furthermore, A/B tests can be performed in online settings.
4. Deployment. The new model is set as the new status quo (e.g. the consumers start getting the recommendations). This usually resets the cycle. A new iteration is started in which Data Engineers might provide new information and Data Scientists find ways to improve the models.
The Black Box Problem
Machine Learning algorithms are often considered to work like black boxes. This means that Data Scientists feed them with data, choose the type of learning that best suits the application in question, sometimes they also tell the machines which features might be relevant for the prediction of the results. After some minutes (or even hours of calculation) the computer spits the results. These results are afterward validated, and new predictions are made. However, in a lot of cases, the Data Scientists do not (and cannot) know how the machine got to the predictions (i.e. what is the combination of features that leads to the prediction made).
Another way of phrasing this is that the models are not interpretable. This is very often (and with justification) seen as a big disadvantage of ML models. Decisions that have great importance to a lot of people are automatically made by these learning algorithms (for example, whether someone is trustworthy enough to get a credit), and the ability to explain why a certain decision has been made, is seen as a reasonable right of the affected people and therefore a necessary characteristic of the models. Although this has not been put into law everywhere, the European Union made a big step in this direction by introducing, since 2018, the right to explanation in the General Data Protection Right (GDPR).
This has become a major concern to the Data Science giants like Google. For example, in November last year, this company launched its Explainable AI services that seeks to give them the edge over Amazon Web Services and Microsoft Azure, in this area. Since they still cannot get direct access to what the model uses as a combination of features to arrive at a particular output, they are developing an interesting approach based on counterfactuals. In an interview with the BBC, Andrew Moore (leader of Google’s Cloud AI division), explained it like this:
The main question is to do these things called counterfactuals, where the neural network asks itself, for example, ‘Suppose I hadn’t been able to look at the shirt colour of the person walking into the store, would that have changed my estimate of how quickly they were walking?’ By doing many counterfactuals, it gradually builds up a picture of what it is and isn’t paying attention to when it’s making a prediction.
In the same interview, Moore recognizes that this is just a step in the right direction and that their approach is far from solving the problem. This approach is said to help ML Engineers make diagnoses of what might be going on but does not guarantee to give the exact explanation. For example, there might be situations where it is still necessary to identify if the detected important aspects are causing the outcome or are just correlated to something that is the true cause.
Some Concluding Remarks
In this post we explored some fundamental concepts for the thriving field of Machine Learning. We also explored what it exactly means for computers to learn and we developed the standard classification of learning algorithms according to the type of data and the learning mechanism that they use to optimize the results. These basic concepts help illuminate the basic machine learning mindset.
Machine Learning algorithms are usually developed and improved in a progressive manner. This feedback loop is described in the traditional Data Science workflow developed by Microsoft. Furthermore, a very important characteristic of most ML algorithms was explored, namely, the fact that most of them work like black boxes that do not allow for interpretation of their outputs. This is a very important research front, that the biggest players like Google are working on.
These concepts are fundamental to understand the Machine Learning mindset. If you have any further questions or comments, or if you need help assessing your Machine Learning needs, please do not hesitate to contact us.



















